
Intro
Planka is a lightweight, open-source, kanban-style project management application similar to Trello. It’s built with React and Postgres, and its key features include a drag-and-drop interface, boards, lists, cards, notifications and markdown support.
Kanban is a simple but powerful method for visualising and managing work. You break tasks into cards and move them through columns that represent stages of progress, such as To Do, In Progress and Done. This makes it easy to see what’s happening at a glance: what’s in the backlog, what’s currently in progress and what’s done. In my case, I’m often juggling projects in my homelab, client work, personal learning goals and content creation. A Kanban board helps me stay organised and focused.
Why I chose Planka
I use and love Trello, but its software is proprietary, and their free plan has limitations on the number of boards you can create. One of my goals with my homelab is digital sovereignty — the ability to control my data, tools and infrastructure without depending on third parties. SaaS platforms are great, but they frequently change pricing, lock down features, or disappear entirely. I want the freedom to own and shape the systems I use every day.
That’s why I self-host as many tools as I can, from DNS and backups to tools like Planka. There’s no shortage of self-hostable Kanban-style tools. I chose Planka because it is Open source, uses a Postgres database, is lightweight and relatively easy to run in Kubernetes. There are some things I don’t like about it, but the pros outweigh the cons. More on that later. Self hosting Planka gives full control over it, I control access to it, its uptime, backups and how it fits into the rest of my workflow.
Kubernetes Set Up
Planka runs as a container and can be deployed to Kubernetes using its official Helm chart. In my homelab, I manage all applications with a GItOps approach using FluxCD. To deploy Planka with Flux CD, I created three manifest files:
- a
HelmRepositoryresource pointing to the official Planka Helm chart, - a
HelmReleasethat defines how Planka should be deployed and configured. - and an
ExternalSecretmanifest to securely fetch credentials from my secret storage.
Using this approach keeps my deployment reproducible, version-controlled, and easy to update.
Defining the Helm Repository
In FluxCD terminology, a HelmRepository points FluxCD to an upstream Helm chart. The Helm Repository below points Flux to the upstream source of the Planka Helm chart:
apiVersion: source.toolkit.fluxcd.io/v1 kind: HelmRepository metadata: name: planka namespace: flux-system spec: interval: 60m url: http://plankanban.github.io/planka
The spec.interval field specifies how often Flux will check the upstream Helm repository for updates. This interval is useful for ensuring that the Planka in my cluster stays up-to-date with the latest versions of Helm charts in the repository without requiring manual intervention.
Managing Secrets with ExternalSecrets
To keep sensitive data like database credentials and the secret key out of Git and plain Kubernetes manifests, I created the secrets in AWS and referenced the secrets using the ExternalSecrets operator. It connects to a secure secrets vault — in my case, AWS SSM Parameter Store — fetches the values, and creates Kubernetes Secret resources automatically inside the cluster.
To create the secrets in the AWS SSM Parameter Store, I used the AWS CLI to define each key-value pair securely. For example, I created and stored the Planka PostgreSQL credentials using the following command:
export planka_db_username="planka_user"
export planka_db_name="planka_db"
aws ssm put-parameter --name "/K8s/Clusters/Prod/Planka/planka-postgres" \
\ --type "SecureString" \
\ --value "{\"username\": \"$planka_db_username\", \"password\": \"$(openssl rand -base64 16)\", \"database\": \"$planka_db_name\"}"This parameter name or secret is namespaced under “Planka” in AWS to keep things organised. Secrets are encrypted at rest using AWS KMS and are only accessible to the IAM role or user associated with the External Secrets provider. Once created and stored, the External Secrets Operator fetches the secrets and injects them into Kubernetes as native Secret resources, making them available to the Planka Helm release without ever exposing the raw values in the Git Repo. Pretty cool!
To make the secrets available inside Kubernetes, I created an ExternalSecret resource that maps each AWS SSM parameter to a corresponding key in a Kubernetes Secret. Here’s an example of the manifest I used:
---
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: planka-secret
namespace: default
spec:
refreshInterval: 1h
secretStoreRef:
name: aws-parameter-store
kind: ClusterSecretStore
target:
name: planka-secret
creationPolicy: Owner
data:
- secretKey: secretkey
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-secretkey
property: SECRET_KEY
- secretKey: planka-db-username
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-postgres
property: username
- secretKey: planka-db-password
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-postgres
property: password
- secretKey: planka-db-name
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-postgres
property: database
- secretKey: planka-admin-email
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-admin
property: admin_email
- secretKey: planka-admin-password
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-admin
property: admin_password
- secretKey: planka-admin-username
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-admin
property: admin_username
- secretKey: planka-admin-adminname
remoteRef:
key: /K8s/Clusters/Prod/Planka/planka-admin
property: admin_nameThe manifest tells the External Secrets Operator to:
- Pull secrets from a
ClusterSecretStorenamedaws-parameter-store - Fetch parameters such as
SECRET_KEYandplanka-db-password from SSM - Map each SSM parameter to a corresponding key in the resulting
Secret
The Planka Helm Release(defined in the next section) then references this Secret to inject the values as environment variables into the container at run time, keeping the credentials secure and fully managed through GitOps.
Creating the Helm Release
A HelmRelease configures and deploys applications via Helm in a cluster. I used the release below to deploy Planka to my cluster.
apiVersion: helm.toolkit.fluxcd.io/v2
kind: HelmRelease
metadata:
name: planka
namespace: default
spec:
interval: 5m
chart:
spec:
chart: planka
version: "1.0.3"
sourceRef:
kind: HelmRepository
name: planka
namespace: flux-system
interval: 60m
valuesFrom:
- kind: Secret
name: planka-secret
valuesKey: secretkey
targetPath: secretkey
- kind: Secret
name: planka-secret
valuesKey: planka-db-username
targetPath: postgresql.auth.username
- kind: Secret
name: planka-secret
valuesKey: planka-db-password
targetPath: postgresql.auth.password
- kind: Secret
name: planka-secret
valuesKey: planka-db-name
targetPath: postgresql.auth.database
values:
base:
baseUrl: "https://planka.ndlovucloud.co.zw"
ingress:
enabled: true
className: nginx
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
hosts:
- host: planka.ndlovucloud.co.zw
paths:
- path: /
pathType: Prefix
tls:
- hosts:
- planka.ndlovucloud.co.zw
secretName: planka-tls
# Values from planka-secret
postgresql:
enabled: true
redis:
enabled: trueThis Helm Release references the Planka external secret from the previous section, pulls in the credentials and injects them into the Planka container at runtime.
How I use Planka
I haven’t started using Planka heavily yet, as I just finished setting it up, but I plan to use it a a central board for managing my personal growth, homelab activities and client projects.
For personal projects, I’ll track blog posts, conference talks, and books I’m reading to stay on top of my goals. I’ll create a dedicated board for infrastructure tasks to log homelab issues, upgrades and experiments. Finally, I’ll use Planka to manage client tasks. Using kanban for this will keep my work organised and deadlines clear.
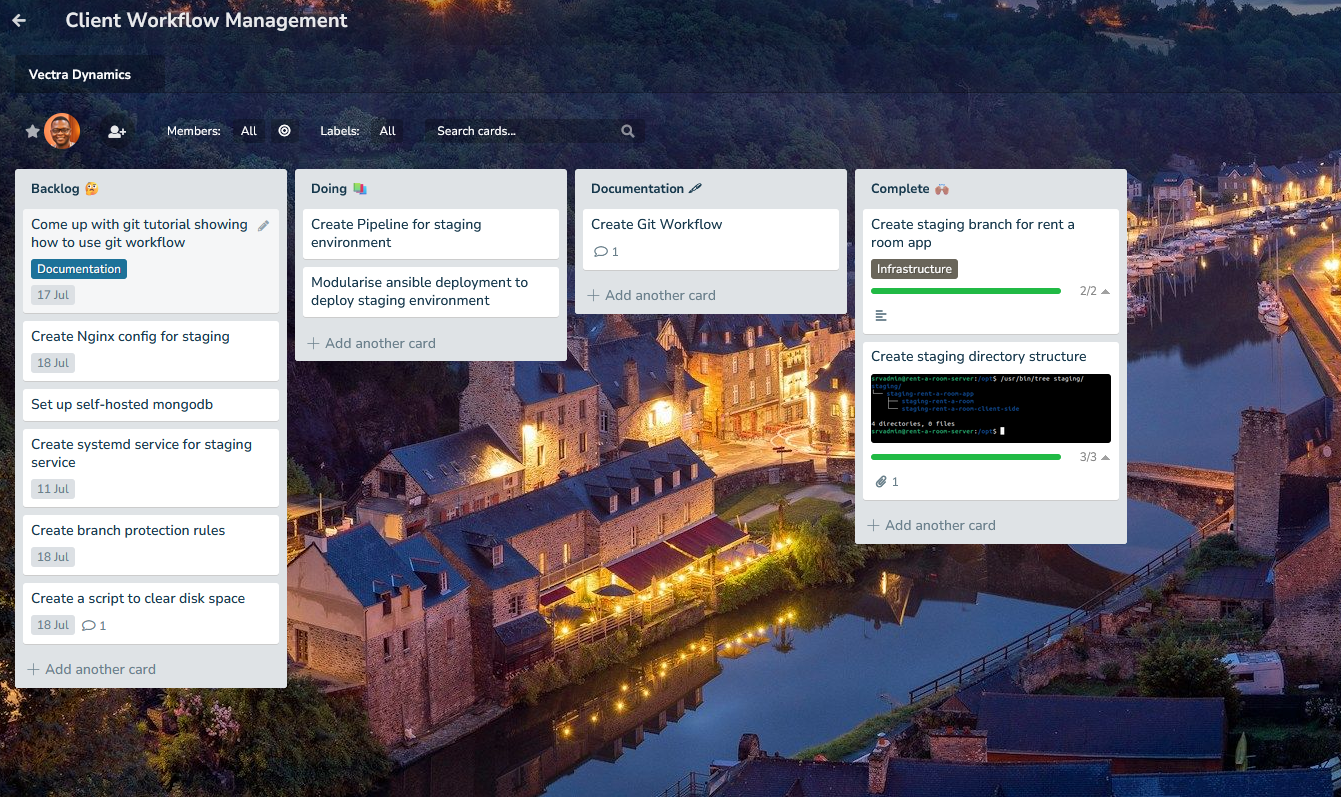
Here’s a screenshot showing the board I’m using to track work I’m doing for a client:
What I don’t like about Planka
I appreciate the work the developers put into Planka, but there are a few areas where I think it falls short.
First, customising parts of the UI isn’t straightforward. Unlike Trello, where you can tweak the look and feel easily, Planka requires you to fork the codebase and edit the CSS to make visual changes to the UI. I’m technically capable of doing that, but I’d prefer an easier way to personalise the interface without maintaining a fork.
Secondly, there’s no built-in search for cards –at least as of the version I’m using. That makes it hard to find specific cards. That’s not a problem for me now because my boards are still small, but as my boards grow, it might be an inconvenience.
Finally, I haven’t found an easy way to export your data in JSON or other portable formats. This is something I’d like to see supported, both for backup and interoperability reasons. These aren’t deal breakers, but they are small annoyances worth noting.
Conclusion
Planka isn’t the most feature-packed project management tool out there, but it’s simple and easy to self-host, perfect for someone like me who wants full control over their data without unnecessary complexity. I’m happy to have a private, minimal Kanban system that fits into my workflow. As my boards grow and usage continues, I may post more about it and how I use it.