
This is the fourth article of many where I write about everything I’m learning about the AWS cloud. The last article was on load balancers. In this post, I’ll talk about scalability.
Navigation
2. EC2 Storage
4. Auto Scaling (This article)
Scalability
Scalability refers to the ability of a system to handle a growing amount of work or demand. Scalability allows a system to handle increased demand by adding additional capacity. This allows the system to handle peak demand without compromising performance or availability. There are two main types of scalability:
- Vertical scalability: This type of scalability is achieved by adding more resources to a system, such as more RAM, CPU, or storage space. There is a hardware limit to how much you can scale vertically. In AWS, scaling vertically could mean changing the EC2 instance type from t2.nano with 0.5GB RAM to a u-12tb.Imetal instance with 12TB of RAM. Examples of services that scale vertically are RDS and ElasticCache. Scaling vertically can also be referred to as scaling up or down.
- Horizontal scalability: Horizontal scalability is achieved by increasing the number of instances in the system. This can be achieved by replicating the system or using a load balancer to distribute the traffic across multiple instances. The instances are grouped together into logical groups called auto scaling groups. Scaling horizontally is also referred to as scaling out/scaling in.
Auto Scaling Groups
An Auto Scaling Groups (ASG) is a collection of EC2 instances that are managed together for the purposes of automatic scaling. The ASG ensures that your application has the resources it needs to perform well even as the demand changes. It works by launching enough instances to meet the application’s desired capacity. It maintains this number of instances by performing periodic health checks on the instances in the group. The Auto Scaling group continues to maintain a fixed number of instances even if an instance becomes unhealthy. If an instance becomes unhealthy, the group terminates the unhealthy instance and launches another instance to replace it. You can use scaling policies to increase or decrease the number of instances in your group dynamically to meet changing conditions.
Capacity
ASGs allow you to dynamically scale out(add more instances) to match increased load or scale in(remove instances) to match decreased load. You can use auto scaling groups to ensure you have a minimum and maximum number of instances running, automatically register new instances with a load balancer and terminate & recreate unhealthy EC2 instances. In AWS, Auto Scaling Groups are free, you only pay for the underlying resources that they manage.
- Minimum Capacity: The least or minimum number of instances that can run at any given time.
- Desired Capacity: The default number of EC2 instances that you want to run most of the time.
- Maximum Capacity: The largest or maximum number of EC2 instances that can be running in the auto scaling group at any time. Setting this upper limit prevents AWS Auto Scaling from creating too many instances which can lead to unexpected costs.
Configuring an Auto Scaling Group
When you create an auto scaling group, you must specify all the information necessary to configure the AWS EC2 instances, the Availability Zones and VPC subnets for the instances, the desired capacity, and the minimum and maximum capacity limits. This information is configured in a Launch Template.
Here’s a longer list of information you can include in launch templates:
– Amazon Machine Image(AMI) and the type of instance to use
– EC2 user data (if any) any scripts or commands to run on the instances after they are launched
– Information about what EBS volumes instances can use
– Security Groups that will be attached to the instances
– SSH keys
– IAM Roles for the EC2 instances
– Network and Subnet information
– Load Balancer information
– scaling policies
It is possible to have multiple versions of a launch template, and this is useful for building different types of EC2 instances using common parameters.
Auto Scaling can also be achieved through CloudWatch alarms. CloudWatch monitors metrics such as average CPU usage for all ASG instances and allows you to create policies for scaling out (adding more instances) and scaling out (reducing the number of instances). The next section discusses scaling policies.
Scaling Policies
Scaling policies are a set of rules that AWS Auto Scaling uses to automatically scale your Auto Scaling Groups. These policies can be used to scale your ASG based on usage metrics such as CPU, memory utilisation and the number of concurrent users. AWS offers two types of scaling policies; Dynamic Scaling and Predictive Scaling.
Dynamic Scaling
There are three types of dynamic scaling policies:
- Target Tracking Scaling: This is the easiest scaling policy to set up. When applied, the policy scales your ASGs to maintain a target value for a metric you define. For example, let’s say you have an application that runs on two EC2 instances in an ASG, and you want the average CPU usage of the ASG to stay at or around 50 percent. If the load on your instances increases, the Auto Scaling Group creates and adds new instances until their average CPU usage is 50 percent. Once the load decreases, the ASG removes the extra instances.
- Simple or Step Scaling: Step scaling policies scale ASGs in steps, based on a single metric. For example, when a CloudWatch alarm for CPU usage above 70 percent is triggered you can use step scaling to add two instances to the system. The second step can be linked to a lower bound of the same metric such as removing a single unit when the CPU usage goes below 30 percent.
- Scheduled Actions: Scheduled actions help you set your own scaling schedule based on predictable load changes. For example, let’s say traffic on your application increases after 5PM on Fridays, remains high to Sunday night and starts to decrease on Monday. You can create a scheduled action to increase capacity (scale out) on Fridays and decrease capacity (scale in) on Monday.
Predictive Scaling
This type of scaling is similar to scheduled actions with only one difference, it uses machine learning to predict capacity requirements! Predictive scaling scales in advance of daily or weekly patterns in traffic. Most scaling strategies are reactive but predictive scaling helps you launch instances based on load forecast. Predictive scaling uses a machine learning algorithm to predict your system’s capacity requirements based on historical logs from CloudWatch. The algorithm learns from historical data and calculates capacity that best fits the load pattern and continues to learn based on new data to make future forecasts more accurate. This is cool.
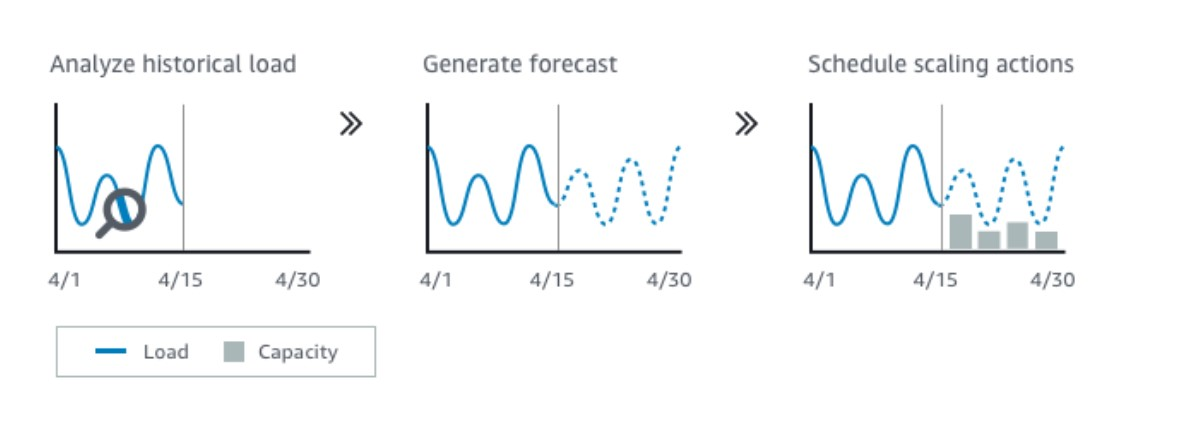
Predictive scaling is best suited for predictable workloads that have a recurring pattern that is specific to a day of the week or time of day.
Scaling Considerations
- AWS enforces scaling cool down periods on instances after a scaling activity. The EC2 instances go into a cooldown period of 5 minutes or 300 seconds to allow metrics to stabilise. During the cooldown period, the ASG does not terminate or launch new instances.
- To reduce the cooldown period and serve requests faster, consider using an AMI to cut down the time it takes to spin up a new EC2 instance.
- Instances can be recreated using an updated launch template using the AWS Instance Refresh feature instead of replacing them manually. This is useful if you have many instances to update.
- You can use the following metrics to scale instances:
CPUUtilization: Average CPU utilisation across all instancesRequestCountPerTarget: The average number of requests received by each instance in a target group- Average Network in/out: This makes sense for network bound apps
- Custom metric: Use a custom metric configured in CloudWatch.
Conclusion
That is all for scalability for now. In the next article I’ll dive into Database services available on AWS.