
Introduction
Kubernetes is an Open-Source project originally developed by Google. It is used for container orchestration or, put simply for managing containers on multiple computers.
I plan to build a home lab to self-host my side projects and other applications I need. My goal in doing this is to simulate real-world production environments and to gain experience with managing Kubernetes clusters, container orchestration, networking and to experiment in an environment I’m not afraid to break. I don’t have any hardware to build on at the moment so I’m setting everything up using virtual machines on my computer. I’ll apply the information I learn from this project to the “real” cluster once I get the equipment I need to build a mini data center.
In this post, I’ll explain the steps I took to build a Kubernetes cluster from scratch using K3S in virtual machines.
Setting up the cluster
Before you can run a Kubernetes cluster, you need nodes or servers to install the Kubernetes software on. My desktop runs on Windows, so I used Hyper-V to create virtual machines to host the cluster. My cluster has four virtual machines; a control node and 3 worker nodes all in the same network and running K3S. The VMs are in a /24 network with DHCP and DNS managed by dnsmasq. The image below shows my current cluster setup:
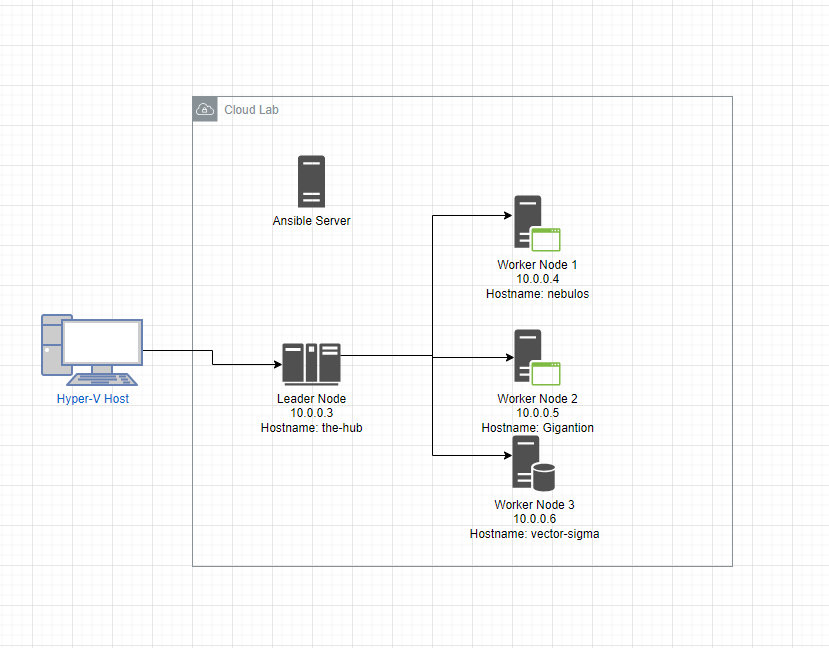
The Ansible server isn’t part of the Kubernetes cluster, but it’s in the same network and what I used to set up the four cluster nodes. Initially, I wanted to use Ansible to provision the servers and to set up everything end to end, but I ended up only using it to provision the servers and not using it to set up Kubernetes because I ran into configuration issues with my initial setup. I couldn’t join the worker nodes to the cluster successfully via Ansible, so I decided to set up Kubernetes manually to get the cluster up and running. For future setups, I’ll use the official K3S Ansible playbook, which should take care of the issues I faced.
For the base OS on the servers, I went with my preferred OS; Ubuntu Server. Each of the servers has 4GB of RAM, 24GB of disk, and a static IP. Using Ansible, I automated the user account set up, software updates and configuring SSH access to the nodes.
Key Components and configuration
After provisioning the servers, it was time to set up Kubernetes. A Kubernetes cluster consists of a control plane and one or more worker nodes. The control plane is a group of processes that manage Kubernetes nodes. It is responsible for controlling which applications run, and the images they use. It manages scheduling, networking and the general state of the cluster. The worker nodes are the machines that run the applications managed by the cluster.
I used K3S in my cluster because it is a lightweight, stripped-down version of Kubernetes that’s ideal for running on resource-constrained devices like Raspberry PIs I plan to use in my home lab cluster. K3S can be installed through a shell script:
Installing K3S on the lead node
curl -sfL https://get.k3s.io | sh -
The command above installs K3s as a systemd service and many other useful cluster and container management tools like kubectl, crictl, ctr, k3s-killall.sh and k3s-uninstall.sh. The installation script creates a kubeconfig file that contains information about the cluster in /etc/rancher/k3s/k3s.yaml. This file is used by kubectl to determine how to communicate with the cluster.
Installing K3S on worker nodes
After installing K3S using the script above, the leader node becomes a single-node cluster. To join the other nodes to the cluster, I ran the command below on each node and set two environment variables; K3S_URL and K3S_TOKEN pointing to the leader node. The K3S_URL is the hostname or IP address of the leader node. The K3S_TOKEN is used by the worker nodes to authenticate with the control plane running on the leader node, the token confirms that the node has permission to join the cluster. This token is stored on the leader node at /var/lib/rancher/k3s/server/node-token.
# Point the worker nodes to the leader node and supply its token curl -sfL https://get.k3s.io | K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh - # Example curl -sfL https://get.k3s.io | K3S_URL=https://the-hub:6443 K3S_TOKEN=WB9M05DmGQh6fARsvM4rEWiz0eoNNTNWb9QMGwZYpW4= sh -
the leader node, take note of the node’s IP address or hostname and copy it’s K3S_TOKEN from /var/lib/rancher/k3s/server/node-token.
If you have a firewall like IP Tables or UFW running, you’ll need to open up the TCP port 6443 that Kubernetes uses to communicate with nodes and add rules to allow traffic from the networks it creates(10.42.0.0/16 and 10.43.0.0/16).
ufw allow 6443/tcp #apiserver ufw allow from 10.42.0.0/16 to any #pods ufw allow from 10.43.0.0/16 to any #services
Adding the K3S environment variables in the worker nodes causes K3s to start K3s in agent or worker mode. This setup is similar to how you’d set up a Docker Swarm cluster where you generate a token on the server node and add or join worker nodes to the cluster using the leader nodes’ token.
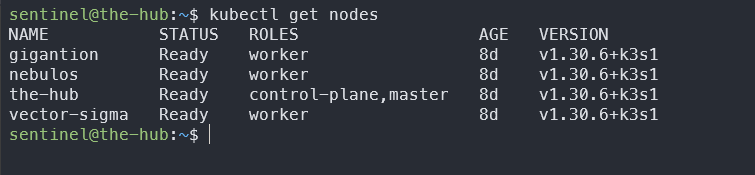
With everything installed, my four-node cluster was up and running. The picture below shows the output of running kubectl get nodes, a command that shows the health and status of a Kubernetes Cluster. There are three worker nodes and one master node. I named the nodes after planets from the Transformers franchise because I like Transformers and one of the apps I planned to deploy to this cluster is a searchable Transformers API and database that I’m building.
Deploying applications
I have only one application running in the cluster right now, but the steps to deploying an application to a Kubernetes cluster are similar. You need to 1) containerise the app, push it to an image registry like Docker Hub, 2) create Kubernetes manifests for the application, 3) set up networking, storage and any app-specific configuration, 4) apply the configuration to the cluster.
Containerise Application
I built an Image of the Transformers API and pushed it to Docker Hub. Kubernetes will pull this image from Docker Hub when it deploy the application. It doesn’t handle the building of images because its focus is on running containers in a cluster. Building the container images is a different concern that requires tools like Docker.
Create Kubernetes Manifests
Manifests in Kubernetes are the YAML or JSON configuration files that let you define the desired state of your application in a Kubernetes cluster. Manifests are similar to Docker Compose files, you can use them to specify things like the image of the app you want to deploy, the number of replicas it should have and what nodes your application should run on. The manifests I’m discussing here are excerpts to explain some of the concepts, for the full list of manifests I used for this project, checkout the code in the project GitHub repo.
Here is an example of a manifest file from the Transformers API:
apiVersion: apps/v1
kind: Deployment
metadata:
name: transformers-deployment
spec:
replicas: 3
selector:
matchLabels:
app: transformers
template:
metadata:
labels:
app: transformers
spec:
containers:
- name: transformers-web
image: vndlovu/transformers-app
ports:
- containerPort: 8000
env:
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_PASSWORD
- name: POSTGRES_DB
value: transformers_db
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodenameThis manifest instructs Kubernetes to run the transformers-web application with 3 replicas on port 8000 and specifies environment variables for database credentials. To deploy this app successfully, I created manifests for other components like networking and database storage. After deployment, exposing the application to the rest of the network is necessary.
Networking and Persistent Storage
I set up an ingress controller, and storage volumes for the application’s Postgress database. In the context of Kubernetes, an ingress controller is used to route HTTP traffic to different services in the cluster. These controllers are based on Nginx, Traefik or HAProxy and allow you to specify for example that traffic to service-a.example.com should be directed to Service A and service-b.example.com be directed to Service B.
In the configuration below, I set up HTTP routing for the transformers web application on port 8000:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: transformers-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /?(.*)
pathType: ImplementationSpecific
backend:
service:
name: transformers-service
port:
number: 8000Next, I set up the configuration necessary to store data in a Postgres database. Kubernetes abstracts the underlying storage, so it’s necessary to create configurations that will allow storage to work on different environments as long as the correct volume is available:
apiVersion: v1
kind: PersistentVolume
metadata:
name: postgres-pv
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/postgres"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2GiThis configuration defines two Kubernetes resources, a PersistentVolume and a PersistentVolumeClaim. The Persistent Volume Claim is a request to Kubernetes for storage and the Persistent Volume is the actual storage resource.
External access with MetalLB
Kubernetes does not provide network load balancers for bare-metal clusters out of the box. To configure load balancers in cloud environments like AWS, Azure and GCP, Kubernetes makes an API call to the cloud provider’s API to provision a load balancer and external IP. Once the load balancer is provisioned, it populates the “External IP” information in load balancer. When running Kubernetes in a bare-metal cluster, Load Balancer external IPs remain in a “pending” state indefinitely when created. The solution is to use something like MetalLB to create external IPs for your load balancers.
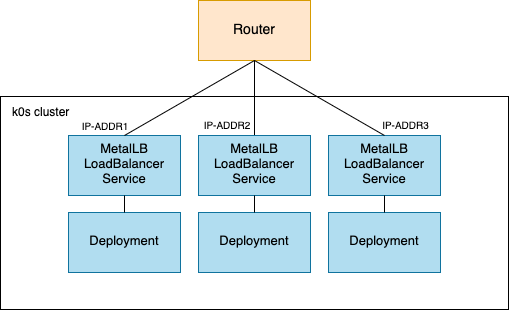
In Layer 2 mode, which is what I used for a simple network like mine, MetalLB uses ARP (Address Resolution Protocol) to respond to requests for an external IP address. When a service is exposed via MetalLB, it “claims” one of the IPs from the specified pool you assign to it and responds to ARP requests from other devices on the same local network, making the service accessible externally. I found it pretty cool that it works with public IPs and RFC1819 (private) IP addresses. For more complex setups, MetalLB can be configured as a BGP speaker to announce the assigned IP address to the network’s routers. I don’t know much about BGP so I’ll leave it at that.
This image demonstrates how MetalLB works. When a LoadBalancer service is requested, MetalLB allocates an IP address from the configured range and makes the network aware that the IP “lives” in the cluster:
Installing MetalLB
I used Helm to add MetalLB to my cluster by running the commands below:
helm repo add metallb https://metallb.github.io/metallb helm install metallb metallb/metallb
The first command tells Helm where to find the MetalLB Helm chart repository and the second one installs MetalLB into the Kubernetes cluster using the Helm chart.
Configure
MetalLB needs a pool of IP addresses it can use for the cluster. I reserved 5 IP addresses between 10.0.0.5 and 10.0.0.10, which were not part of my dnsmasq DHCP pool. Assigning IPs outside the DHCP range prevents conflicts with dynamically assigned IPs in the network. A single IP address would have sufficed for my simple set-up, but I plan to add more services to the cluster and I might need distinct IPs for each. I created the following custom resource to configure MetalLB and named the file metallb-config.yaml:
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: pool namespace: default # or any other namespace spec: addresses: - 10.0.0.5-10.0.0.10 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2-advertisement namespace: default spec: addresspools: - pool
This configures MetalLB with a pool of IPs it can use and to advertise those IP addresses using Layer 2 mode.
For more information about MetalLB and how to configure it, refer to the official MetalLB documentation.
Lessons Learned
Setting up a Kubernetes cluster is easier to do in cloud environments, where most of the infrastructure and services are managed for you. However, deploying Kubernetes in my network, while challenging helped me gain a better understanding of the process and underlying architecture. I configured the nodes, and networking and manually set up the control plane and worker nodes.
I used Helm to install MetalLB and liked how convenient it is for deploying and configuring services in clusters in a consistent way.
Conclusion
Looking forward, the next step to extend this cluster is to add more applications to it. I’m going to add services I want to self-host like BitWarden, a media server like Plex and a file-hosting solution like NextCloud. Additionally, I’ll transition to real hardware once I purchase and set everything I need up.